이제서야 받은 꿀커피를 먹어봤는데... 되게 신기한 맛... 꿀과... 커피...?
1. 인덱스
- 데이터를 빠르게 찾을 수 있도록 도와주는 도구
* 클러스터형 인덱스 : 기본 키로 지정하면 자동 생성, 테이블에 1개만 만들 수 있음
기본 키로 지정한 열을 기준으로 자동 정렬
* 보조 인덱스 : 고유 키로 지정하면 자동 생성되며 여러 개를 만들 수 있음. But 자동 정렬을 되지 않음.
✓ 장점 : SELECT 문으로 검색하는 속도가 매우 빨라짐
컴퓨터의 부담이 줄어들어서 전체 시스템의 성능이 향상됨
✓ 단점 : 공간 차지로 인해 데이터베이스 안에 추가적인 공간 필요
처음 인덱스를 만들 시 시간이 오래 걸릴 수 있음.
2. 균형 트리
- 클러스터형 인덱스와 보조 인덱스는 모두 내부적으로 균형 트리로 만들어짐
* 노드 ( 페이지 page )
- 데이터가 저장되는 공간
루트 노드 - 중간 노드 - 리프 노드
[ 관련 명령어 ]
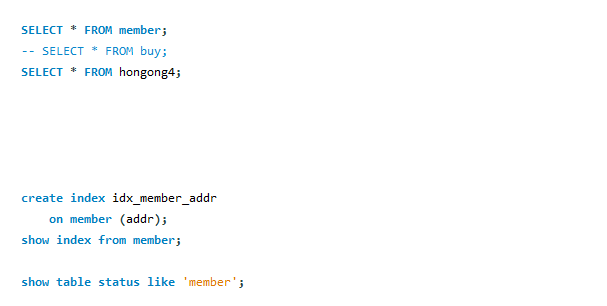
* 테이블 인덱스 확인 : show index from 테이블이름
key_name : primary라면 기본 키로 설정해서 자동으로 생성된 인덱스
column_name : 해당 열에 인덱스가 만들어짐
Non_unique : 중복이 허용되지 않는 인덱스
- 0 : false
- 1 : true
보조 인덱스는 여러개 만들 수 있음 => 하지만! 많이 만들 수록 데이터베이스의 공간을 많이 차지하므로 효율이 좋지 않음!
* 인덱스 크기 확인
- show table status like '테이블 이름'
* 단순 보조 인덱스 생성
- create index 테이블 이름 on 테이블이름(열 이름);
* 인덱스 적용
- analyze table 테이블 이름
* 고유 보조 인덱스 생성
- create unique index 인덱스 이름 on 테이블 이름(열 이름)
: 중복 데이터를 허용 안 함
=> 이미 중복 데이터가 있을 시 인덱스를 만들 수 없음
[ 숙제 ]
- key_name이 primary로 출력된 결과 화면 캡쳐!